哈希算法有时候被称之为摘要,这个比喻有点不精确,因为摘要毕竟还是要让人看懂的,而哈希算法后的数字,人是完全读不懂的。而且我们哈希后的字符串可能比原文还要长,所以这个比喻不太恰当。
简单来说,通过哈希算法:
同样的输入一定会有同样的输出。但你拿输出要想还原输入则不可能。
无论多长或者多短的输入,输出都是一样长的。
改动一点点,输出就会完全不一样,且毫无规律。
用点例子就秒懂了。
from hashlib import sha256
my_string = “Hello”
sha256_digest = sha256(my_string).hexdigest()
print sha256_digest
我们这里用Python现成的库来实验SHA256算法。
运行结果:
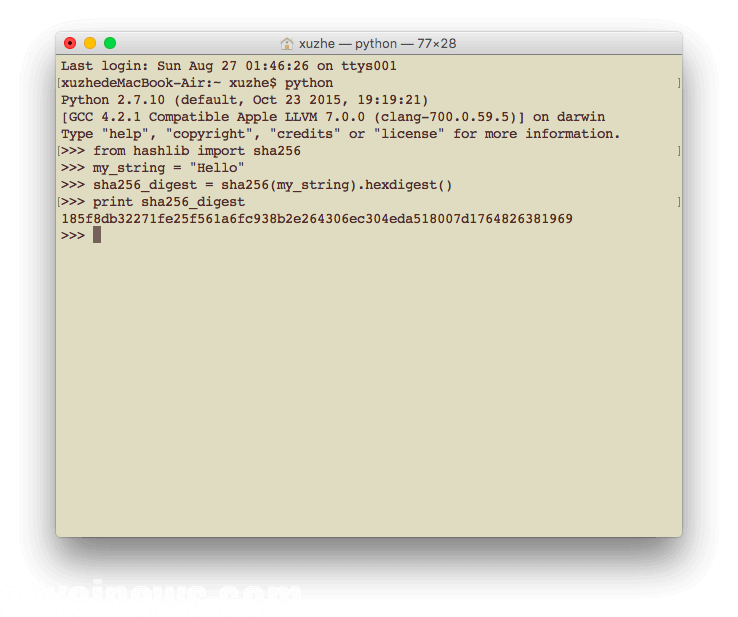
输出:185f8db32271fe25f561a6fc938b2e264306ec304eda518007d1764826381969
完全看不懂是什么,重点是当我们知道输出是185f8db32271fe25f561a6fc938b2e264306ec304eda518007d1764826381969
完全没办法还原成原始信息Hello,但这不是随机数。
只要输入信息一致,结果肯定是完全一样:
same_string=”Hello”
sha256_digest = sha256(same_string).hexdigest()
print sha256_digest
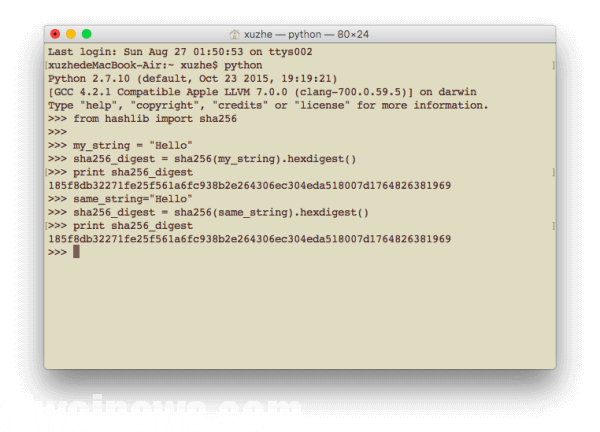
如果输入有哪怕一点点小小的不一样,结果会完全不同,并且完全无法预测。
diff=”hello”
sha256_digest = sha256(diff).hexdigest()
print sha256_digest
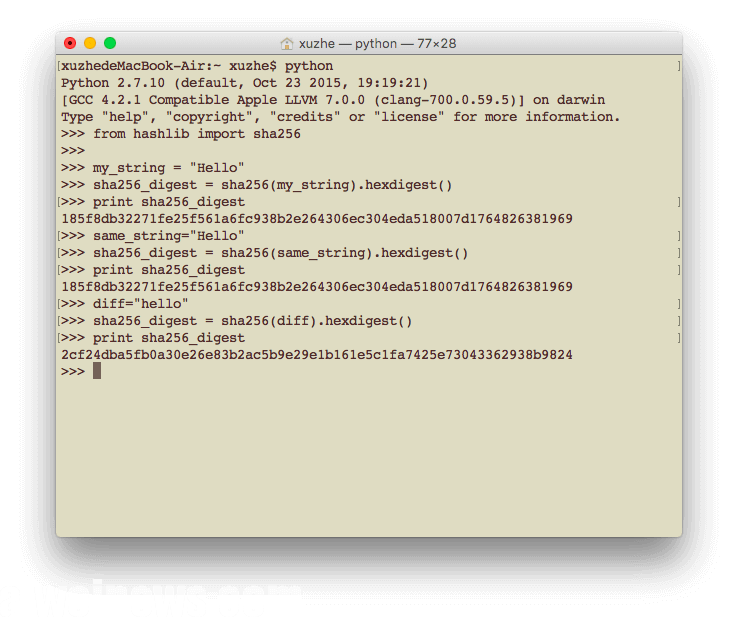
只是把Hello的第一个字母改成小写的h,两者的结果完全看不出联系。
2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824这个结果和185f8db32271fe25f561a6fc938b2e264306ec304eda518007d1764826381969是看不出啥联系的,这个效应称之为“雪崩效应”。
也就是说,哪怕任何一点点不同的输入都能保证有不同的输出,并且不可逆。
并且,长度不一样的信息哈希后,长度是一致的。
long_string=”The quick brown fox jumps over the lazy dog”
sha256_digest = sha256(long_string).hexdigest()
print sha256_digest
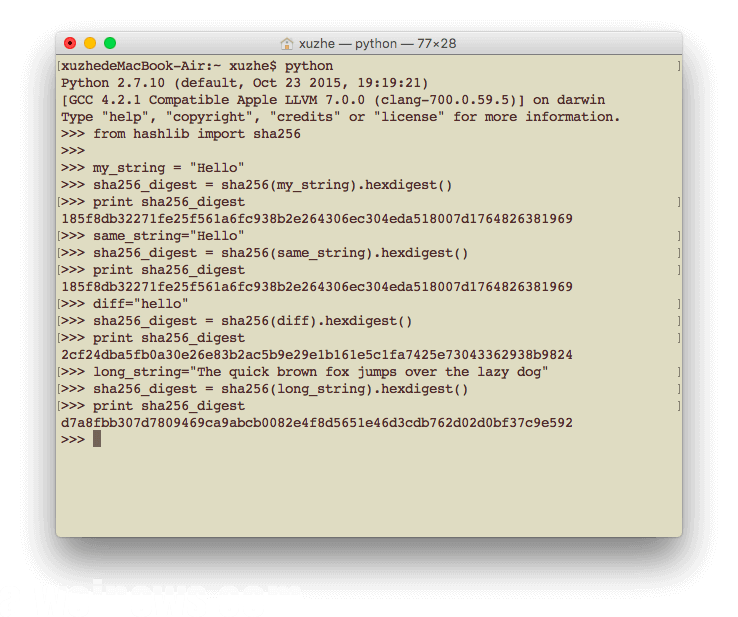
不同长度的字符串哈希后,结果的长度是一致的。
这里有个问题,输出的字符串的长度必然是一致的话,哈希的结果应该是有穷的。但我们输入的信息可能性是无穷的,这意味着必然有“撞车”事件发生。理论上是的,但不必担心,这种事情发生的概率很小,可以忽略不计。
哈希算法的用处很多,比如我们验证文件下载是否完整时,就会应用到。因为哪怕一个字节有不一样,雪崩效应也会让哈希后的值完全不一样,所以哈希值一样可以保证你下载的文件和上传者的完全一致。
这里的SHA1值就是一个哈希值,下载完文件后跑同样的算法,如果结果和这个一致,那就证明一个字节都不差,可以放心。
另外一个比较多的应用场景是储存你的密码,你在注册一个网站的时候,网站后台的数据库是不存储你的密码的,因为这样做不安全。万一网站的数据库被泄露了,用户的密码就都泄露了,但网站又要验证你的密码,怎么办呢?用哈希算法。
第一次注册的时候,你的密码哈希后存储在数据库里,当你下次登录的时候密码再哈希一次,和存储的哈希值对比。如果完全一致,这证明密码键入和注册的时候一样。这样网站不用知道你的密码,还能验证你的密码。
考虑到有些用户的密码十分简单,大量使用诸如abcd1234这样的密码,那我们事先把常用的密码哈希过后结果存起来,和网站泄露的数据库一对比,就能知道用户的密码是什么了。这种攻击方法确实存在,应对的办法是“加盐”,用户注册密码的时候,在密码后追加一个字符串,只有网站自己知道。验证的时候同样追加一个字符串,这样密码一致的时候,哈希值也会是一样的。但是攻击者不知道盐是什么样的字符串,这种攻击也就无效了。
关于哈希算法的其他应用还有很多,重点了解数字签名算法。
发表回复