之前准备发这个帖子,被禁言了,可能是因为违规图床,或者是代码有问题,不敢发了,所以,部分代码都以贴图代替,也移除了链接(果然是对链接理解不同,我理解的是带点击跳转的才叫链接)。
疑似违规的图床,是一个叫贴图库的网站,生成的图片地址是 i2.piimg.com,如果是违规的请大家告诉我,因为我在搜索本站的时候,并未搜索到相应的地址。
前阵子看到有兄弟发了个脚本抓豆瓣的姑娘们,觉得挺有意思的,果然还是懂点技术流弊啊,其实我这帖子也请教了他。
最近迷上了汤不热(Tumblr),比较喜欢看上面的真人实拍的视频,心想着能不能自动去下载视频,然后放到我的谷歌屌丝版的VR眼镜里去欣赏,虽然都不长,但是毕竟是真人实拍,和AV还是有区别的。
于是上网找了一下有没有这样的脚本,发现已经有很多了,但是都不是很完美,于是,我准备自己动手改。找到一个看起来能用的脚本,于是就开始了我的改造计划。
要改造是因为汤不热(Tumblr)页面的结构经常变动,页面结构一变,代码也要跟着变,而且视频的地址可能会经过多重跳转,可不是,在发这个文章之前,我发现前几天写的代码不能用了,因为界面结构变了,所以要调整。
这个脚本只能下载视频,不含图片,我觉得图片上网看看就好了,而且只是视频的地址,虽然Python有很多库可以直接下载,但是毕竟不是专业的,保存好地址可以放到迅雷了批量下载。ps:不知道为什么,有些地址在浏览器里可以很快速度下载,但是迅雷就没速度,不知道为啥,如果遇到迅雷没速度的,可以用浏览器直接下载。
版本是Python 2,有兴趣的,可以去谷歌一下Python2环境的搭建,我这里就不详细说了,我千言万语的表达,都胜过你去看个教程。遇到所有的错误,都可以在Google上找到。有问题我会尽量解答,无奈有回复限制。
代码如下:
import sys, getopt,wget
import time,re,os,requests,urllib2
import sys
from bs4 import BeautifulSoup#ss搭理配置,其他代理自己改
proxies = {
\”http\”: \”socks5://127.0.0.1:1080\”,
\”https\”: \”socks5://127.0.0.1:1080\”,
}reload(sys)
sys.setdefaultencoding( \”utf-8\” )
#———– 爬取tumblr图片和视频 ———–
class TumblrClass:
def __init__(self):
self.clear_video=0
self.clear_img=0
self.img_path=”
self.video_path=”
self.index_url=”
self.curPage=1
self.video_url_file=”
self.img_url_file=”
self.headers = {
‘Host’:self.index_url.replace(‘http://’,”),
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0’,
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,
‘Accept-Language’: ‘zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3’,
‘Accept-Encoding’: ‘gzip, deflate’,
‘Referer’: self.index_url,
‘Connection’: ‘keep-alive’,
‘Cache-Control’: ‘max-age=0’
}
self.se = requests.Session()
def set_headers(self,reUrl):
self.headers = {
‘Host’:self.index_url.replace(‘http://’,”).strip(‘/’),
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0’,
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,
‘X-Requested-With’:’XMLhttpRequest’,
‘Accept-Language’: ‘zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3’,
‘Accept-Encoding’: ‘gzip, deflate’,
‘Referer’: reUrl,
‘Connection’: ‘keep-alive’,
‘Cache-Control’: ‘max-age=0′
}def get_blogs_in_file(self,fileName):
blogList=[]
inFile=open(fileName,’r’)
for line in inFile:
blogList.append(line.replace(‘\n’,”))
return blogList
def get_img_urls(self,text):
img_urls=[]
return img_urls
def get_video_urls(self,text):
r = BeautifulSoup(text,\”html.parser\”)
iframes = r.find_all(‘iframe’,src=re.compile(\”https://www.tumblr.com/video/\”))
video_urls=[]
for iframe in iframes:
newSrc = iframe[‘src’]
video_urls.append(newSrc)return video_urls
def get_video_files(self,url):
url=url.strip(‘/’)
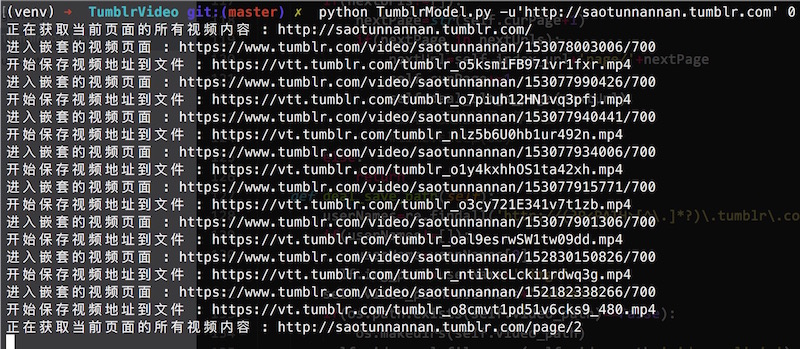
print ‘进入嵌套的视频页面 : ‘+url
#———————————————————–
self.set_headers(url)
self.headers={
‘Host’: ‘www.tumblr.com’,
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0’,
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,
‘Accept-Language’: ‘zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3’,
‘Accept-Encoding’: ‘gzip, deflate, br’,
‘Connection’: ‘keep-alive’
}
Reslut=self.se.get(url,headers=self.headers,proxies=proxies)soup = BeautifulSoup(Reslut.text,\”html.parser\”)
links = soup.find_all(‘source’)
for link in links:
originUrl = link.get(‘src’)
originType = link.get(‘type’)#获取真正的URL
r = self.se.get(originUrl,headers=self.headers,proxies=proxies,allow_redirects = False)
trueUrl = r.headers[‘Location’]
if ‘#_=_’ in trueUrl:
trueUrl = trueUrl.replace(‘#_=_’,”)return trueUrl
def save_video_file(self,url,path):
url=self.get_video_files(url)
print ‘开始保存视频地址到文件 : ‘+url
self.video_url_file.write(url+’\n’)
self.video_url_file.flush()def deal_blogs_page(self,url):
print ‘正在获取当前页面的所有视频内容 : ‘+url
self.set_headers(url)
Result=self.se.get(url,headers=self.headers,proxies=proxies)
text=Result.text
video_urls=self.get_video_urls(text)for videoUrl in video_urls:
self.save_video_file(videoUrl,self.video_path)
nextUrls=re.findall(‘href=\\”/page/(?P<next>\d+)\\”‘,text)
if(nextUrls!=[]):
nextPage=str(self.curPage+1)
if(nextPage in nextUrls):
nextUrl=self.index_url+’page/’+nextPage
self.curPage+=1
self.deal_blogs_page(nextUrl)
#抓取一页的时候,停60秒
#time.sleep(60)
else:
return
def deal_save_path(self):
userNames=re.findall(‘http://(?P<PATH>[^\.]*?)\.tumblr\.com/’,self.index_url)
if(userNames!=[]):
userName=userNames[0]
self.img_path=userName+’/img/’
self.video_path=userName+’/videos/’
if(os.path.exists(self.video_path)==False):
os.makedirs(self.video_path)
self.video_url_file=open(self.video_path+’video_url’,’w’)def display_progress(width, percent):
percent=int(percent)
print \”%s %d%%\r\” % ((‘%%-%ds’ % width) % (width * percent / 100 * ‘=’), percent),
if percent >= 100:
sys.stdout.flush()def update_display(self,received,file_size):
percent = received*100.0/file_size
if percent > 100:
percent = 100.0
self.display_progress(100,percent)def main(self,type,value,isSave):
self.isSave=isSave
if(type==’b’):
if(re.match(‘^[http://]’,value)==False):
self.index_url=’http://’+value.strip(‘/’)+’/’
else:
self.index_url=value.strip(‘/’)+’/’
self.set_headers(self.index_url)
self.deal_save_path()
self.deal_blogs_page(self.index_url)
elif(type==’f’):
urlList=self.get_blogs_in_file(value)
for url in urlList:
if(re.match(‘^[http://]’,url)==False):
self.index_url=’http://’+url.strip(‘/’)+’/’
else:
self.index_url=url.strip(‘/’)+’/’
self.deal_save_path()
self.deal_blogs_page(self.index_url)
def __del__(self):
self.video_url_file.close()if __name__ == ‘__main__’:
tc=TumblrClass()
type=”
values=”
isSave=0
if(len(sys.argv)!=3):
print ‘Input number Error!’
print ‘python ‘+sys.argv[0]+’ -u[url] or -f[fileName] [0/1]’
exit()
opts, args = getopt.getopt(sys.argv[1:], \”hu:f:h:s:\”)
for op, value in opts:
if(op==’-u’):
type=’b’
values=value
elif(op==’-f’):
type = ‘f’
values=value
else:
print ‘python ‘+sys.argv[0]+’ -u[url] or -f[fileName] [0/1]’
exit()
isSave=sys.argv[2]
#print isSave
tc.main(type,values,isSave)
这是保存之后的文本文件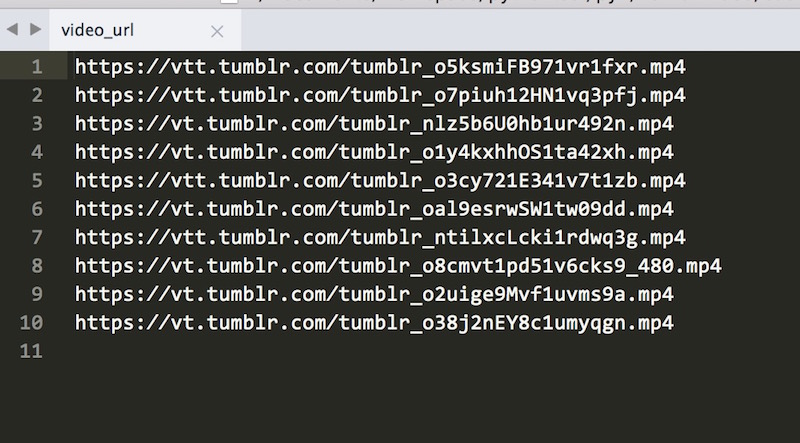
 下面是是代码需要的库
下面是是代码需要的库
以上源程序作者是 waitig(Github) ,但是不能发链接,我就署名好了,因为源程序年久失修,几近不能用,我修复了一些bug,并且修改了抓取的方式,还增加了使用代理(因为汤不热现在中国打不开,你懂的),精简了代码。
发表回复